作为Glide的第二篇,主要分析了Glide请求中数据来源,或者说Glide的缓存机制。Glide构建过程会配置很多注册项,然后在获取数据时,会根据已有的信息,如dataClass等,然后找到合适的ModelLoader、Decoder、Transcoder等,经历了四个缓存历程,没有找到合适的缓存,最终从网络拉取数据。
在上文Glide流程分析 分析with、load、into函数三步骤时,略过了最重要的步骤:数据获取。本节从into函数中的engile.load函数开始,分析Glide如何从不同的地方加载数据。这里需要记住参数modelClass、resourceClass和transcodeClass的实参分别是String.class、Object.class和Drawable.Class,而model=https://xxm-sz/github.io/test.png。
resourceClass通常代表原始数据解码后的资源类型,dataClass代表原始数据类型,transcodeClass代表采样,解码后的资源类型。modelClass代表我们Glide.with(context).load(xxx)函数中load函数参数xxx的类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 public <R> LoadStatus load ( GlideContext glideContext, Object model, Key signature, int width, int height, Class<?> resourceClass, Class<R> transcodeClass, Priority priority, DiskCacheStrategy diskCacheStrategy, Map<Class<?>, Transformation<?>> transformations, boolean isTransformationRequired, boolean isScaleOnlyOrNoTransform, Options options, boolean isMemoryCacheable, boolean useUnlimitedSourceExecutorPool, boolean useAnimationPool, boolean onlyRetrieveFromCache, ResourceCallback cb, Executor callbackExecutor) long startTime = VERBOSE_IS_LOGGABLE ? LogTime.getLogTime() : 0 ; EngineKey key = keyFactory.buildKey( model, signature, width, height, transformations, resourceClass, transcodeClass, options); EngineResource<?> memoryResource; synchronized (this ) { memoryResource = loadFromMemory(key, isMemoryCacheable, startTime); if (memoryResource == null ) { return waitForExistingOrStartNewJob( glideContext, model, signature, width, height, resourceClass, transcodeClass, priority, diskCacheStrategy, transformations, isTransformationRequired, isScaleOnlyOrNoTransform, options, isMemoryCacheable, useUnlimitedSourceExecutorPool, useAnimationPool, onlyRetrieveFromCache, cb, callbackExecutor, key, startTime); } } cb.onResourceReady( memoryResource, DataSource.MEMORY_CACHE, false ); return null ; }
engile.load函数通过各种信息计算出EngineKey,然后通过loadFromMemory函数从内存获取资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Nullable private EngineResource<?> loadFromMemory( EngineKey key, boolean isMemoryCacheable, long startTime) { if (!isMemoryCacheable) { return null ; } EngineResource<?> active = loadFromActiveResources(key); if (active != null ) { return active; } EngineResource<?> cached = loadFromCache(key); if (cached != null ) { return cached; } return null ; }
isMemoryCacheable默认情况下等于true,先调用了loadFromActiveResources函数从活动资源获取资源,如果获取不到,再调用loadFromCache函数从内存获取资源。
loadFromActiveResources先分析从loadFromActiveResources资源获取活动资源。这里的活动资源指的已经设置到Target后释放的,没有Target引用到的,垃圾回收器还没有回收的资源的,Glide可以重新获取设置给新的Target。
1 2 3 4 5 6 7 8 private EngineResource<?> loadFromActiveResources(Key key) { EngineResource<?> active = activeResources.get(key); if (active != null ) { active.acquire(); } return active; }
ActiveResources对象在Engine引擎被创建时初始化,内部持有一个HashMap类型的``activeEngineResources变量,以Key为键,ResourceWeakReference为值。通过get`函数去获取资源的弱引用。
1 2 3 4 5 6 7 8 9 10 11 12 synchronized EngineResource<?> get(Key key) { ResourceWeakReference activeRef = activeEngineResources.get(key); if (activeRef == null ) { return null ; } EngineResource<?> active = activeRef.get(); if (active == null ) { cleanupActiveReference(activeRef); } return active; }
如果能获取到活动资源EngineResource,调用其activate函数,并返回该活动资源,然后通过回调设置给Target了。
1 2 3 4 5 6 7 8 9 10 synchronized void activate (Key key, EngineResource<?> resource) ResourceWeakReference toPut = new ResourceWeakReference( key, resource, resourceReferenceQueue, isActiveResourceRetentionAllowed); ResourceWeakReference removed = activeEngineResources.put(key, toPut); if (removed != null ) { removed.reset(); } }
activate只是新建ResourceWeakReference实例,然后放到activeEngineResources中。
loadFromCache从活动缓存获取不到资源,就调用loadFromCache函数从内存缓存获取资源。
1 2 3 4 5 6 7 8 private EngineResource<?> loadFromCache(Key key) { EngineResource<?> cached = getEngineResourceFromCache(key); if (cached != null ) { cached.acquire(); activeResources.activate(key, cached); } return cached; }
调用了getEngineResourceFromCache函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private EngineResource<?> getEngineResourceFromCache(Key key) { Resource<?> cached = cache.remove(key); final EngineResource<?> result; if (cached == null ) { result = null ; } else if (cached instanceof EngineResource) { result = (EngineResource<?>) cached; } else { result = new EngineResource<>( cached, true , true , key, this ); } return result; }
getEngineResourceFromCache函数的逻辑也是非常易懂,不过多介绍。这里的cache是MemoryCache类型,在GlideBuilder的build函数创建Glide时,会创建MemoryCache的实现类LruResourceCache并传递给Engine实例。LruResourceCache继承自LruCache类,并实现MemoryCache接口。而LruCache内部维护着LinkedHashMap,用于存取缓存。
所以如果从LruChache中能得到缓存,也会回调将资源设置给Target.
waitForExistingOrStartNewJob该函数主要是从不同的来源去加载目标资源,有可能是本地磁盘缓存,也有可能是网络资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 private <R> LoadStatus waitForExistingOrStartNewJob ( GlideContext glideContext, Object model, Key signature, int width, int height, Class<?> resourceClass, Class<R> transcodeClass, Priority priority, DiskCacheStrategy diskCacheStrategy, Map<Class<?>, Transformation<?>> transformations, boolean isTransformationRequired, boolean isScaleOnlyOrNoTransform, Options options, boolean isMemoryCacheable, boolean useUnlimitedSourceExecutorPool, boolean useAnimationPool, boolean onlyRetrieveFromCache, ResourceCallback cb, Executor callbackExecutor, EngineKey key, long startTime) EngineJob<?> current = jobs.get(key, onlyRetrieveFromCache); if (current != null ) { current.addCallback(cb, callbackExecutor); if (VERBOSE_IS_LOGGABLE) { logWithTimeAndKey("Added to existing load" , startTime, key); } return new LoadStatus(cb, current); } EngineJob<R> engineJob = engineJobFactory.build( key, isMemoryCacheable, useUnlimitedSourceExecutorPool, useAnimationPool, onlyRetrieveFromCache); DecodeJob<R> decodeJob = decodeJobFactory.build( glideContext, model, key, signature, width, height, resourceClass, transcodeClass, priority, diskCacheStrategy, transformations, isTransformationRequired, isScaleOnlyOrNoTransform, onlyRetrieveFromCache, options, engineJob); jobs.put(key, engineJob); engineJob.addCallback(cb, callbackExecutor); engineJob.start(decodeJob); return new LoadStatus(cb, engineJob); }
上面代码中jobs是Jobs类对象,Jobs类持有HashMap类型的jobs和onlyCacheJobs,根据onlyRetrieveFromCache在两者切换。HashMap的Value是EngineJob类,是一个Glide请求加载管理类,当加载完成会通过回调通知。如果能获取到EngineJob对象,说明已经有相同的任务在进行中。
如果Jobs对象中获取不到EngineJob,则通过工厂新建一个EngineJob对象和DecodeJob对象,并调用其engineJob.start函数。这里DecodeJob类负责从缓存数据或原始数据解码,转换出目标资源类型。
1 2 3 4 5 6 7 8 9 10 11 public synchronized void start (DecodeJob<R> decodeJob) this .decodeJob = decodeJob; GlideExecutor executor = decodeJob.willDecodeFromCache() ? diskCacheExecutor : getActiveSourceExecutor(); executor.execute(decodeJob); } boolean willDecodeFromCache () Stage firstStage = getNextStage(Stage.INITIALIZE); return firstStage == Stage.RESOURCE_CACHE || firstStage == Stage.DATA_CACHE; }
start函数通过线程池去执行DecodeJob对象。在看DecodeJob的run函数之前,先看看相关线程池的创建。
DiskCacheExectorGlideBuilder的build函数会将下面提到的线程池都创建,这里先看 diskCacheExecutor。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 diskCacheExecutor = GlideExecutor.newDiskCacheExecutor(); public static GlideExecutor newDiskCacheExecutor () return newDiskCacheBuilder().build(); } public static GlideExecutor.Builder newDiskCacheBuilder () { return new GlideExecutor.Builder( true ) .setThreadCount(DEFAULT_DISK_CACHE_EXECUTOR_THREADS) .setName(DEFAULT_DISK_CACHE_EXECUTOR_NAME); } public GlideExecutor build () if (TextUtils.isEmpty(name)) { throw new IllegalArgumentException( "Name must be non-null and non-empty, but given: " + name); } ThreadPoolExecutor executor = new ThreadPoolExecutor( corePoolSize, maximumPoolSize, threadTimeoutMillis, TimeUnit.MILLISECONDS, new PriorityBlockingQueue<Runnable>(), new DefaultThreadFactory(name, uncaughtThrowableStrategy, preventNetworkOperations)); if (threadTimeoutMillis != NO_THREAD_TIMEOUT) { executor.allowCoreThreadTimeOut(true ); } return new GlideExecutor(executor); } }
这里线程池的核心线程和最大线程数都设置成了1,即单线程线程池。
1 2 3 4 5 private GlideExecutor getActiveSourceExecutor () return useUnlimitedSourceGeneratorPool ? sourceUnlimitedExecutor : (useAnimationPool ? animationExecutor : sourceExecutor); }
SourceExecutorsourceExecutor的创建:
1 2 3 4 5 6 7 8 9 10 11 sourceExecutor = GlideExecutor.newSourceExecutor(); public static GlideExecutor newSourceExecutor () return newSourceBuilder().build(); } public static GlideExecutor.Builder newSourceBuilder () { return new GlideExecutor.Builder( false ) .setThreadCount(calculateBestThreadCount()) .setName(DEFAULT_SOURCE_EXECUTOR_NAME); }
与磁盘缓存线程池创建的区别是线程数的计算。
1 2 3 4 5 6 7 public static int calculateBestThreadCount () if (bestThreadCount == 0 ) { bestThreadCount = Math.min(MAXIMUM_AUTOMATIC_THREAD_COUNT, RuntimeCompat.availableProcessors()); } return bestThreadCount; }
MAXIMUM_AUTOMATIC_THREAD_COUNT=4,所以资源线程池的线程多少取决于设备CPU核心数量,且最多为4。
AnimationExecutoranimationExecutor线程的创建亦是如此,不过它逻辑是这样,当CPU核心数大于4,线程数设为2,否则设为1.
1 2 3 4 5 6 7 8 9 public static GlideExecutor.Builder newAnimationBuilder () { int bestThreadCount = calculateBestThreadCount(); int maximumPoolSize = bestThreadCount >= 4 ? 2 : 1 ; return new GlideExecutor.Builder( true ) .setThreadCount(maximumPoolSize) .setName(DEFAULT_ANIMATION_EXECUTOR_NAME); }
UnlimitedSourceExecutorGlide还创建了无限制的线程池。
1 2 3 4 5 6 7 8 9 10 11 12 13 GlideExecutor.newUnlimitedSourceExecutor() public static GlideExecutor newUnlimitedSourceExecutor () return new GlideExecutor( new ThreadPoolExecutor( 0 , Integer.MAX_VALUE, KEEP_ALIVE_TIME_MS, TimeUnit.MILLISECONDS, new SynchronousQueue<Runnable>(), new DefaultThreadFactory( DEFAULT_SOURCE_UNLIMITED_EXECUTOR_NAME, UncaughtThrowableStrategy.DEFAULT, false ))); }
这里直接创建线程池,线程池容量无限大(Integer.MAX_VALUE),核心线程为1,10秒存活。
也就是说,默认情况下,Glide会为我们创建四种类型GlideExecutor,它们的主要区别是核心线程数和最大线程数的区别。
diskCacheExecutor:磁盘缓存线程池:核心和最大线程数都是1。sourceExecutor: 数据来源线程池:核心和最大线程数都最大为4,最小取决CPU核心。animationExecutor:动画线程池:CPU核心数大于4,核心和最大线程数设为2,否则设为1unlimitedSourceExecutor:无限制线程池,核心为,最大无限制。
DecodeJob了解完线程池的创建,回到DecodeJob类的run函数。
1 2 3 4 5 6 @Override public void run () ... runWrapped(); ... }
在创建DecodeJob对象的时候,runReason会被赋值为INITIALIZE,所以runWrapped函数这里走的是INITIALIZE分支。该分支有三个重要函数。
getNextStage函数、getNextGenerator函数和runGenerators函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 private void runWrapped () switch (runReason) { case INITIALIZE: stage = getNextStage(Stage.INITIALIZE); currentGenerator = getNextGenerator(); runGenerators(); break ; case SWITCH_TO_SOURCE_SERVICE: runGenerators(); break ; case DECODE_DATA: decodeFromRetrievedData(); break ; default : throw new IllegalStateException("Unrecognized run reason: " + runReason); } }
getNextStage函数的INITIALIZE分支。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 private Stage getNextStage (Stage current) switch (current) { case INITIALIZE: return diskCacheStrategy.decodeCachedResource() ? Stage.RESOURCE_CACHE : getNextStage(Stage.RESOURCE_CACHE); case RESOURCE_CACHE: return diskCacheStrategy.decodeCachedData() ? Stage.DATA_CACHE : getNextStage(Stage.DATA_CACHE); case DATA_CACHE: return onlyRetrieveFromCache ? Stage.FINISHED : Stage.SOURCE; case SOURCE: case FINISHED: return Stage.FINISHED; default : throw new IllegalArgumentException("Unrecognized stage: " + current); } } private DataFetcherGenerator getNextGenerator () switch (stage) { case RESOURCE_CACHE: return new ResourceCacheGenerator(decodeHelper, this ); case DATA_CACHE: return new DataCacheGenerator(decodeHelper, this ); case SOURCE: return new SourceGenerator(decodeHelper, this ); case FINISHED: return null ; default : throw new IllegalStateException("Unrecognized stage: " + stage); } }
默认情况下,默认情况下DiskCacheStrategy是AUTOMATIC,其decodeCachedResource函数和decodeCachedData函数都是返回true。所有getNextStage函数返回Stage.RESOURCE_CACHE,getNextGenerator函数返回ResourceCacheGenerator对象。
而runGenerators函数主要执行Generator的startNext函数。如果startNext函数返回false,则执行下一个策略和对应的Generator。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 private void runGenerators () currentThread = Thread.currentThread(); startFetchTime = LogTime.getLogTime(); boolean isStarted = false ; while (!isCancelled && currentGenerator != null && !(isStarted = currentGenerator.startNext())) { stage = getNextStage(stage); currentGenerator = getNextGenerator(); if (stage == Stage.SOURCE) { reschedule(); return ; } } if ((stage == Stage.FINISHED || isCancelled) && !isStarted) { notifyFailed(); } }
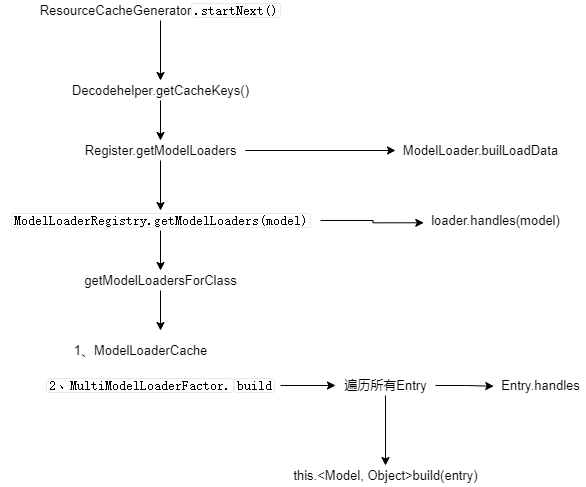
ResourceCacheGeneratorResourceCacheGenerator是我们碰到第一个Generator,主要缓存采样或转换后的资源,利用DiskLruCache在硬盘上进行存取资源。分析起来会比较吃力,但理解了之后,再看DataCacheGenerator和SourceGenerator就简单多了。
startNext看看ResourceCacheGenerator的startNext函数。startNext函数的工作量非常多,分成几个步骤分析。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 @Override public boolean startNext () List<Key> sourceIds = helper.getCacheKeys(); if (sourceIds.isEmpty()) { return false ; } List<Class<?>> resourceClasses = helper.getRegisteredResourceClasses(); if (resourceClasses.isEmpty()) { if (File.class.equals(helper.getTranscodeClass())) { return false ; } throw new IllegalStateException( "Failed to find any load path from " + helper.getModelClass() + " to " + helper.getTranscodeClass()); } while (modelLoaders == null || !hasNextModelLoader()) { resourceClassIndex++; if (resourceClassIndex >= resourceClasses.size()) { sourceIdIndex++; if (sourceIdIndex >= sourceIds.size()) { return false ; } resourceClassIndex = 0 ; } Key sourceId = sourceIds.get(sourceIdIndex); Class<?> resourceClass = resourceClasses.get(resourceClassIndex); Transformation<?> transformation = helper.getTransformation(resourceClass); currentKey = new ResourceCacheKey( helper.getArrayPool(), sourceId, helper.getSignature(), helper.getWidth(), helper.getHeight(), transformation, resourceClass, helper.getOptions()); cacheFile = helper.getDiskCache().get(currentKey); if (cacheFile != null ) { sourceKey = sourceId; modelLoaders = helper.getModelLoaders(cacheFile); modelLoaderIndex = 0 ; } } loadData = null ; boolean started = false ; while (!started && hasNextModelLoader()) { ModelLoader<File, ?> modelLoader = modelLoaders.get(modelLoaderIndex++); loadData = modelLoader.buildLoadData( cacheFile, helper.getWidth(), helper.getHeight(), helper.getOptions()); if (loadData != null && helper.hasLoadPath(loadData.fetcher.getDataClass())) { started = true ; loadData.fetcher.loadData(helper.getPriority(), this ); } } return started; }
getChacheKeys步骤1:DecodeHelper.getCacheKeys函数主要工作遍历getLoadData函数获取到的LoadData列表,将每个LoadData中的sourceKeys对象和alternateKeys集合添加到cacheKeys集合(去掉重复的Key)并返回。这里的key对象用于唯一标识缓存数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 List<Key> getCacheKeys () { if (!isCacheKeysSet) { isCacheKeysSet = true ; cacheKeys.clear(); List<LoadData<?>> loadData = getLoadData(); for (int i = 0 , size = loadData.size(); i < size; i++) { LoadData<?> data = loadData.get(i); if (!cacheKeys.contains(data.sourceKey)) { cacheKeys.add(data.sourceKey); } for (int j = 0 ; j < data.alternateKeys.size(); j++) { if (!cacheKeys.contains(data.alternateKeys.get(j))) { cacheKeys.add(data.alternateKeys.get(j)); } } } } return cacheKeys; }
getLoadDatagetLocadData函数主要通过glideContext.getRegistry().getModelLoaders(model)函数获取ModelLoader列表modelLoaders,并迭代modelLoaders列表,调用每个ModelLoader的buildLoadData函数创建LoadData对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 List<LoadData<?>> getLoadData() { if (!isLoadDataSet) { isLoadDataSet = true ; loadData.clear(); List<ModelLoader<Object, ?>> modelLoaders = glideContext.getRegistry().getModelLoaders(model); for (int i = 0 , size = modelLoaders.size(); i < size; i++) { ModelLoader<Object, ?> modelLoader = modelLoaders.get(i); LoadData<?> current = modelLoader.buildLoadData(model, width, height, options); if (current != null ) { loadData.add(current); } } } return loadData; }
glideContext.getRegistry().getModelLoaders(model)函数最终调用到ModelLoaderRegistry.getModelLoaders(model)函数。
在构建Glide的单例时,会创建Register的实例,而Register会创建其他几个注册类,例如这里的ModelLoaderRegistry,Glide通过Register注册的内容会被代理到具体的注册类,这些注册类或者它们的工厂类会持有各自Entry元素的列表,Glide注册的所有内容(注册项)都以Entry实例被保存到对应列表。也就是它们的工作原理都是类似,然后通过modelClass、resourceClass、transcodeClas等去获取相关配置项。我们会把这些配置项整理成Excel文件,方便筛选。
**ModelLoaderRegistry**是注册类之一,主要持有MultiModelLoaderFactory工厂,所有的操作基本代理到工厂上,例如添加配置项到Entry列表。另外就是ModelLoaderCache缓存,毕竟每次寻找迭代所有配置项是昂贵的操作。MultiModelLoaderFactory工厂类主要根据给定的modelClass和dataClass(原始数据类型,例如InputStream.Class)获取一个或多个ModelLoader(这种寻找或者说映射关系就是所谓的配置项)。
ModelLoader:是一个接口,有很多具体实现类,表示从不同的来源加载不同类型的资源。其buildLoadData函数返回LoadData对象,handles函数表示当前ModelLoader能否处理该model,通过该类型去加载原始数据。
LoadData是ModelLoader的内部类,表示持有一个Key类型变量sourceKey用于标识正在加载的来源(地址)和备选的Key集合alternateKeys指向缓存数据,当没有缓存,通过DataFetcher对象fetcher从来源加载数据。
1 2 3 public <Model> List<ModelLoader<Model, ?>> getModelLoaders(@NonNull Model model) { return modelLoaderRegistry.getModelLoaders(model); }
getModelLoadersgetModelLoaders函数调用了getModelLoadersForClass函数获取了ModelLoader列表modelLoaders,并迭代调用每个ModelLoader对象的handles函数过滤掉不能处理该模型具体内容的ModelLoader。例如列表中ModelLoader实例都能处理String.class,但有的ModelLoader能处理http/https开头的String,而有的不行,所以需要ModelLoader的handles函数再进一步过滤。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public <A> List<ModelLoader<A, ?>> getModelLoaders(@NonNull A model) { List<ModelLoader<A, ?>> modelLoaders = getModelLoadersForClass(getClass(model)); if (modelLoaders.isEmpty()) { throw new NoModelLoaderAvailableException(model); } int size = modelLoaders.size(); boolean isEmpty = true ; List<ModelLoader<A, ?>> filteredLoaders = Collections.emptyList(); for (int i = 0 ; i < size; i++) { ModelLoader<A, ?> loader = modelLoaders.get(i); if (loader.handles(model)) { if (isEmpty) { filteredLoaders = new ArrayList<>(size - i); isEmpty = false ; } filteredLoaders.add(loader); } } if (filteredLoaders.isEmpty()) { throw new NoModelLoaderAvailableException(model, modelLoaders); } return filteredLoaders; }
getModelLoadersForClassgetModelLoadersForClass函数根据model,先在缓存ModelLoaderCache(内部持有HashMap)对象cache获取ModelLoader列表loaders,没有的话再通过工厂MultiModelLoaderFactory对象的build函数创建。注意到创建列表后会缓存到cache中。
1 2 3 4 5 6 7 8 9 private synchronized <A> List<ModelLoader<A, ?>> getModelLoadersForClass( @NonNull Class<A> modelClass) { List<ModelLoader<A, ?>> loaders = cache.get(modelClass); if (loaders == null ) { loaders = Collections.unmodifiableList(multiModelLoaderFactory.build(modelClass)); cache.put(modelClass, loaders); } return loaders; }
multiModelLoaderFactory.build(modelClass)MultiModelLoaderFactory.build函数创建ModelLoader列表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 synchronized <Model> List<ModelLoader<Model, ?>> build(@NonNull Class<Model> modelClass) { try { List<ModelLoader<Model, ?>> loaders = new ArrayList<>(); for (Entry<?, ?> entry : entries) { if (alreadyUsedEntries.contains(entry)) { continue ; } if (entry.handles(modelClass)) { alreadyUsedEntries.add(entry); loaders.add(this .<Model, Object>build(entry)); alreadyUsedEntries.remove(entry); } } return loaders; } catch (Throwable t) { alreadyUsedEntries.clear(); throw t; } }
遍历Entry集合entries,通过每个Entry实例的handles函数判断是否有能力处理该model,能处理的话通过entry.factory.build(this)创建ModelLoader。
Entry类handles函数是判断该Entry能否处理该model,例如,String.class,Uri.class。而ModelLoader子类的handles函数判断是能否处理model类型的内容,例如字符串https://xxm-sz.githuh.io与content://localstorage/data,但有的ModelLoader直接返回true,在buildLoadData函数交给自身持有的ModelLoader或ModelLoader列表去处理。
贴一下到这里的调用图 :
接下来,就涉及到Entry集合entries怎么来,以及Entry怎么创建ModelLoader。
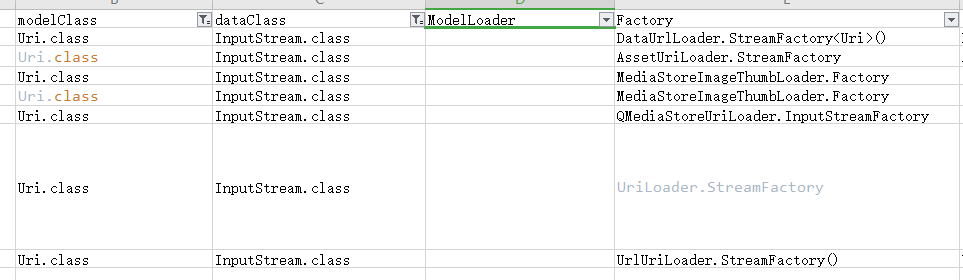
ModelLoaderRegistry在Register创建的时候被实例化,而在GlideBuilder构建建的过程中,会给Register设置超多的配置,这些配置中的Loader配置都会设置给ModelLoaderRegistry,每个配置都会封装成Entry保存到工厂类MultiModelLoaderFactory的entries列表中。而我们例子匹配到下面四个配置项。
看看MultiModelLoaderFactory的build函数如何创建ModelLoader。
1 2 3 4 5 6 loaders.add(this .<Model, Data>build(entry)); private <Model, Data> ModelLoader<Model, Data> build (@NonNull Entry<?, ?> entry) { return (ModelLoader<Model, Data>) Preconditions.checkNotNull(entry.factory.build(this )); }
通过Entry对象持有的Factory对象的build函数来创建ModelLoader实例。Model为String.class对应的factory为上面提到的4种Factory。
DataUrlLoader.StreamFactory:
DataUrlLoader.StreamFacotry的build函数是直接创建了DataUrlLoader对象,并将自身的DataDecoder对象opener作为参数传递给了DataUrlLoader构造函数。DataUrlLoader的decode函数对String进行合法检测,是否符合base64 Image的规范。
StringLoader.StreamFactory()
1 2 3 4 public ModelLoader<String, InputStream> build (@NonNull MultiModelLoaderFactory multiFactory) return new StringLoader<>(multiFactory.build(Uri.class, InputStream.class)); }
StringLoader.StreamFactory().build又调用MultiModelLoaderFactory的build重载函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public synchronized <Model, Data> ModelLoader<Model, Data> build ( @NonNull Class<Model> modelClass, @NonNull Class<Data> dataClass) try { List<ModelLoader<Model, Data>> loaders = new ArrayList<>(); boolean ignoredAnyEntries = false ; for (Entry<?, ?> entry : entries) { if (alreadyUsedEntries.contains(entry)) { ignoredAnyEntries = true ; continue ; } if (entry.handles(modelClass, dataClass)) { alreadyUsedEntries.add(entry); loaders.add(this .<Model, Data>build(entry)); alreadyUsedEntries.remove(entry); } } if (loaders.size() > 1 ) { return factory.build(loaders, throwableListPool); } else if (loaders.size() == 1 ) { return loaders.get(0 ); } else { if (ignoredAnyEntries) { return emptyModelLoader(); } else { throw new NoModelLoaderAvailableException(modelClass, dataClass); } } } catch (Throwable t) { alreadyUsedEntries.clear(); throw t; } }
可见,又是一个从Entry列表中查找Entry对象的过程,只不过这时的modelClass是Uri.Class,dataClass是InputStream.Class。会调用Entry的handles函数表示能否处理该类型。
所以这里返回的将是StringLoader实例,但该实例包含MultiModelLoader对象,该对象持有其他ModelLoader的列表。
StringLoader.FileDescriptorFactory()
这里的FileDescriptorFactory最终也在注册项中匹配到model是Uri.class,data是ParcelFileDescriptor.class。
所以这里返回的也是StringLoader实例,该实例也包含包含MultiModelLoader对象,该对象持有其他ModelLoader的列表。
StringLoader.AssetFileDescriptorFactory()
这里的FileDescriptorFactory最终也在注册项中选择model是Uri.class,data是AssetFileDescriptor.class。
所以这里返回的也是StringLoader实例,但该实例只包含UriLoader。
ModelLoader小结一下:
在Glide创建时,会将Glide能处理的modelClass,dataClass,以及创建Loader的Factory封装成Entry保存ModelLoaderRegistry的工厂类MultiModelLoaderFactory中。在后面发起的Glide请求,根据modelClass去找到合适的ModelLoader,会通过Entry和ModelLoader的handles函数过滤掉不匹配的类型和不能处理具体内容的ModelLoader。
modelLoader.buildLoadData再回到ModelLoaderRegister的getModelLoadersString.class类型的ModelLoaders列表后,迭代列表,调用每个ModelLoader的handles函数,由于StringLoader都返回true,而DataUrlLoader需要判断String以data:image开头,所以这里返回的ModelLoader只有三个。再回到上层函数getLoadData中,迭代modelLoaders列表并调用modelLoader.buildLoadData。
1 2 3 4 5 6 7 8 public LoadData<Data> buildLoadData ( @NonNull String model, int width, int height, @NonNull Options options) Uri uri = parseUri(model); if (uri == null || !uriLoader.handles(uri)) { return null ; } return uriLoader.buildLoadData(uri, width, height, options); }
对于StringLoader中uriLoader是UriLoader类型的实例,其handles函数判断条件,显然与我们的例子不符。
1 2 3 4 5 6 7 8 9 10 11 public boolean handles (@NonNull Uri model) return SCHEMES.contains(model.getScheme()); } private static final Set<String> SCHEMES = Collections.unmodifiableSet( new HashSet<>( Arrays.asList( ContentResolver.SCHEME_FILE, ContentResolver.SCHEME_ANDROID_RESOURCE, ContentResolver.SCHEME_CONTENT)))
对于StringLoader中uriLoader是MultiModelLoader对象的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public LoadData<Data> buildLoadData ( @NonNull Model model, int width, int height, @NonNull Options options) Key sourceKey = null ; int size = modelLoaders.size(); List<DataFetcher<Data>> fetchers = new ArrayList<>(size); for (int i = 0 ; i < size; i++) { ModelLoader<Model, Data> modelLoader = modelLoaders.get(i); if (modelLoader.handles(model)) { LoadData<Data> loadData = modelLoader.buildLoadData(model, width, height, options); if (loadData != null ) { sourceKey = loadData.sourceKey; fetchers.add(loadData.fetcher); } } } return !fetchers.isEmpty() && sourceKey != null ? new LoadData<>(sourceKey, new MultiFetcher<>(fetchers, exceptionListPool)) : null ; }
即调用MultiModelLoader对象中ModeLoader列表中每个modelLoader的handles函数。返回的将是一个包含MultiFetcher的LoadData。而这里符合我们例子的是StringLoader.StreamFactory()对象build生成的MultiModelLoader对象。
在MultiModelLoader对象中modelLoader列表最后一项工厂UrlUriLoader.StreamFactory。看看factory.build函数。
1 2 3 public ModelLoader<Uri, InputStream> build (MultiModelLoaderFactory multiFactory) return new UrlUriLoader<>(multiFactory.build(GlideUrl.class, InputStream.class)); }
返回的是UrlUriLoader对象,其handles函数。
1 2 3 4 5 6 public boolean handles (@NonNull Uri uri) return SCHEMES.contains(uri.getScheme()); } private static final Set<String> SCHEMES = Collections.unmodifiableSet(new HashSet<>(Arrays.asList("http" , "https" )));
也就是说可以处理我们的URL地址。看看其参数,又是找匹配的注册项,生成ModelLoader对象并赋值给UrlUriLoader对象的urlLoader变量。UrlUriLoader的buildLoadData函数是委托给urlLoader对象的。
1 2 3 4 5 public LoadData<Data> buildLoadData( @NonNull Uri uri, int width, int height, @NonNull Options options) { GlideUrl glideUrl = new GlideUrl(uri.toString()); return urlLoader.buildLoadData(glideUrl, width, height, options); }
可见LoadData的sourceKey的值就是mode的值,这时是我们的url。
可见这里匹配到的Loader是HttpGlideUrlLoader。其buildLoadData函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public LoadData<InputStream> buildLoadData ( @NonNull GlideUrl model, int width, int height, @NonNull Options options) GlideUrl url = model; if (modelCache != null ) { url = modelCache.get(model, 0 , 0 ); if (url == null ) { modelCache.put(model, 0 , 0 , model); url = model; } } int timeout = options.get(TIMEOUT); return new LoadData<>(url, new HttpUrlFetcher(url, timeout)); }
所以getLoadData函数最终返回只有一个LoadData对象的列表。该对象的DataFetcher是MultiFetcher。MultiFetcher对象列表中只有HttpUrlFetcher对象。
所以步骤1,getCacheKeys函数返回的是是一个GlideUrl。回到startNext函数的步骤2。
getRegisteredResourceClasses()接着startNextgetRegisteredResourceClasses()函数。
getRegisteredResourceClasses函数先在缓存中获取,获取不到的话通过类似getChacheKeys函数的步骤去步骤获取。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public <Model, TResource, Transcode> List<Class<?>> getRegisteredResourceClasses( @NonNull Class<Model> modelClass, @NonNull Class<TResource> resourceClass, @NonNull Class<Transcode> transcodeClass) { List<Class<?>> result = modelToResourceClassCache.get(modelClass, resourceClass, transcodeClass); if (result == null ) { result = new ArrayList<>(); List<Class<?>> dataClasses = modelLoaderRegistry.getDataClasses(modelClass); for (Class<?> dataClass : dataClasses) { List<? extends Class<?>> registeredResourceClasses = decoderRegistry.getResourceClasses(dataClass, resourceClass); for (Class<?> registeredResourceClass : registeredResourceClasses) { List<Class<Transcode>> registeredTranscodeClasses = transcoderRegistry.getTranscodeClasses(registeredResourceClass, transcodeClass); if (!registeredTranscodeClasses.isEmpty() && !result.contains(registeredResourceClass)) { result.add(registeredResourceClass); } } } modelToResourceClassCache.put( modelClass, resourceClass, transcodeClass, Collections.unmodifiableList(result)); } return result; }
ModelToResourceClassCache类持持有ArrayMap类型的registeredResourceClassCache的变量,键值对为<MultiClassKey``List<Class>>,存取内容都是操作该变量的元素。而MutilClassKey则是以modelClass,resourceClass,TranscodeClass来作为hash,equeas函数计算的条件。
在没有缓存的情况,通过一下步骤获取:
DataClass列表
获取DataClasses列表
通过modelLoaderRegistry.getDataClasses函数获取dataClass列表。ModelLoaderRegistry和MultiModelLoaderFactory在前面已经分析过了,这里快速过一遍。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public synchronized List<Class<?>> getDataClasses(@NonNull Class<?> modelClass) { return multiModelLoaderFactory.getDataClasses(modelClass); } synchronized List<Class<?>> getDataClasses(@NonNull Class<?> modelClass) { List<Class<?>> result = new ArrayList<>(); for (Entry<?, ?> entry : entries) { if (!result.contains(entry.dataClass) && entry.handles(modelClass)) { result.add(entry.dataClass); } } return result; }
也就是遍历Entry列表,判断entry能否处理modelClass,能的话加到列表result,迭代结束后返回result。按照我们的列子,返回的dataClass列表应该只有InputStream.class、ParcelFileDescriptor.class、AssetFileDescriptor.class。
ResourceClass列表
获取resourceClass列表
在Registry的构造函数中,创建ResourceDecoderRegistry对象之后,会调用setResourceDecoderBucketPriorityList函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 setResourceDecoderBucketPriorityList( Arrays.asList(BUCKET_GIF, BUCKET_BITMAP, BUCKET_BITMAP_DRAWABLE)) public synchronized void setBucketPriorityList (@NonNull List<String> buckets) List<String> previousBuckets = new ArrayList<>(bucketPriorityList); bucketPriorityList.clear(); for (String bucket : buckets) { bucketPriorityList.add(bucket); } for (String previousBucket : previousBuckets) { if (!buckets.contains(previousBucket)) { bucketPriorityList.add(previousBucket); } } }
此时modifiedBuckets列表的内容应该是[BUCKET_PREPEND_ALL,BUCKET_GIF, BUCKET_BITMAP, BUCKET_BITMAP_DRAWABLE,BUCKET_APPEND_ALL],都是String元素,然后调用ResourceDecoderRegistry对象的setBucketPriorityList函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 public synchronized void setBucketPriorityList (@NonNull List<String> buckets) List<String> previousBuckets = new ArrayList<>(bucketPriorityList); bucketPriorityList.clear(); for (String bucket : buckets) { bucketPriorityList.add(bucket); } for (String previousBucket : previousBuckets) { if (!buckets.contains(previousBucket)) { bucketPriorityList.add(previousBucket); } } }
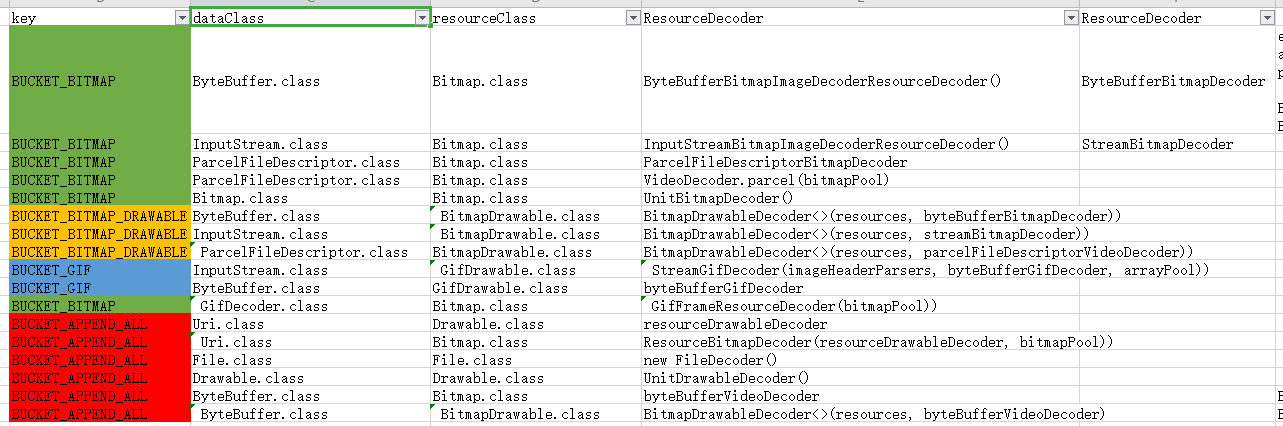
这样就把modifiedBuckets列表的内容按序添加到了bucketPriorityList。这里主要在于添加顺序,从而更改不同的优先级。而在创建Glide时,也会将一些配置也会以Entry的形式注册到ResourceDecoderRegistry中。ResourceDecoderRegistry持有下面两个属性,bucketPriorityList用于保存前面提到的String类型的BUCKET,而decoders用于保存Glide的对ResourceDecoderRegistry的注册项。Entry持有的Class类型的dataClass,resourceClass和ResourceDecoder类型的decoder。
1 2 private final List<String> bucketPriorityList = new ArrayList<>(); private final Map<String, List<Entry<?, ?>>> decoders = new HashMap<>();
通过Excel文件来看看ResourceCacheRegister中的注册项。
resourceClass只有Bitmap.class、BitmapDrawable.class 、GifDrawable.class,Drawable.class四种类型。
回到getRegisteredResourceClasses()函数,在获取dataClass列表后,调用了decoderRegistry.getResourceClasses函数获取resourceClass列表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 decoderRegistry.getResourceClasses(dataClass, resourceClass); public synchronized <T, R> List<Class<R>> getResourceClasses( @NonNull Class<T> dataClass, @NonNull Class<R> resourceClass) { List<Class<R>> result = new ArrayList<>(); for (String bucket : bucketPriorityList) { List<Entry<?, ?>> entries = decoders.get(bucket); if (entries == null ) { continue ; } for (Entry<?, ?> entry : entries) { if (entry.handles(dataClass, resourceClass) && !result.contains((Class<R>) entry.resourceClass)) { result.add((Class<R>) entry.resourceClass); } } } return result; }
getResourceClasses函数中的bucketPriorityList的元素为key,遍历Entry列表,判断每个Entry实例能否处理该dataClass和resourceClass,能的话添加到result列表,并返回result。按照我们的列子,因为dataClass有InputStream.class、ParcelFileDescriptor.class、AssetFileDescriptor.class,而resourceClass是默认的Object.class。按照前面的注册项,再按key排序,这里返回resourceClass列表有[GifDrawable.class,Bitmap.class,BitmapDrawable.class ]
TranscodeClass列表
获取transcodeClass列表
同样``TranscoderRegistry注册类会在Registry构造函数中被创建,在Glide构造函数中被装配。TranscoderRegistry只持有一个Entry的列表。Entry持有Class类型的fromClass,toClass和ResourceTransocder类型的transcoder`。
1 private final List<Entry<?, ?>> transcoders = new ArrayList<>();
Glide构建过程会对``TranscoderRegistry`实例的注册项进行装配,通过Excel文件筛选。
回到getRegisteredResourceClasses()函数,在获取resourceClass列表后通过getTranscodeClasses函数获取transcodeClass列表。函数参数transcodeClass可能是Drawable.class、Bitmap.class、GifDrawable.class,File.class。而在我们的例子中是默认的Drawable.class。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public synchronized <Z, R> List<Class<R>> getTranscodeClasses(@NonNull Class<Z> resourceClass, @NonNull Class<R> transcodeClass{ List<Class<R>> transcodeClasses = new ArrayList<>(); if (transcodeClass.isAssignableFrom(resourceClass)) { transcodeClasses.add(transcodeClass); return transcodeClasses; } for (Entry<?, ?> entry : transcoders) { if (entry.handles(resourceClass, transcodeClass)) { transcodeClasses.add(transcodeClass); } } return transcodeClasses; }
回到Registry的getRegisteredResourceClasses函数中获取transcodeClass列表之后,判断并添加到result列表中。
1 2 3 4 5 6 7 8 9 for (Class<?> registeredResourceClass : registeredResourceClasses) { List<Class<Transcode>> registeredTranscodeClasses = transcoderRegistry.getTranscodeClasses(registeredResourceClass, transcodeClass); if (!registeredTranscodeClasses.isEmpty() && !result.contains(registeredResourceClass)) { result.add(registeredResourceClass); } }
所以startNext函数中返回的最终resourceClass列表是[Bitmap.class、BitmapDrawable.class、GifDrawable.class]
回到startNext
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 while (modelLoaders == null || !hasNextModelLoader()) { resourceClassIndex++; if (resourceClassIndex >= resourceClasses.size()) { sourceIdIndex++; if (sourceIdIndex >= sourceIds.size()) { return false ; } resourceClassIndex = 0 ; } Key sourceId = sourceIds.get(sourceIdIndex); Class<?> resourceClass = resourceClasses.get(resourceClassIndex); Transformation<?> transformation = helper.getTransformation(resourceClass); currentKey = new ResourceCacheKey( helper.getArrayPool(), sourceId, helper.getSignature(), helper.getWidth(), helper.getHeight(), transformation, resourceClass, helper.getOptions()); cacheFile = helper.getDiskCache().get(currentKey); if (cacheFile != null ) { sourceKey = sourceId; modelLoaders = helper.getModelLoaders(cacheFile); modelLoaderIndex = 0 ; } }
尝试遍历步骤1获取到的Key列表和步骤2获取到resourceClass列表的每个元素,以及其他元素,计算出ResourceCacheKey对象,然后通过
helper.getDiskCache().get(currentKey)在磁盘缓存获取。
DiskLruCache1 2 3 DiskCache getDiskCache () { return diskCacheProvider.getDiskCache(); }
通过追溯diskCacheProvider来源,在Engine的build函数有如下代码:
1 DecodeJob<R> result = Preconditions.checkNotNull((DecodeJob<R>) pool.acquire());
而pool则是Engine的静态内部类DecodeJobFactory的一个对象池。
1 2 3 4 5 6 7 8 9 final Pools.Pool<DecodeJob<?>> pool = FactoryPools.threadSafe( JOB_POOL_SIZE, new FactoryPools.Factory<DecodeJob<?>>() { @Override public DecodeJob<?> create() { return new DecodeJob<>(diskCacheProvider, pool); } });
DecodeJobFactory的创建追溯到Engine的构造器中
1 2 3 4 5 6 7 8 9 10 this .diskCacheProvider = new LazyDiskCacheProvider(diskCacheFactory)if (decodeJobFactory == null ) { decodeJobFactory = new DecodeJobFactory(diskCacheProvider); } if (diskCacheFactory == null ) { diskCacheFactory = new InternalCacheDiskCacheFactory(context); }
所有这里diskCacheProvider定位到时LazyDiskCacheProvider的实例,而factory是InternalCacheDiskCacheFactory。再查看其getDiskCache函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public DiskCache getDiskCache () if (diskCache == null ) { synchronized (this ) { if (diskCache == null ) { diskCache = factory.build(); } if (diskCache == null ) { diskCache = new DiskCacheAdapter(); } } } return diskCache; } }
先通过factory.build函数创建diskCache,创建失败则创建DiskCacheAdapter实例。定位到InternalCacheDiskCacheFactory类的父类DiskLruCacheFactory的build函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 public DiskCache build () File cacheDir = cacheDirectoryGetter.getCacheDirectory(); if (cacheDir == null ) { return null ; } if (cacheDir.isDirectory() || cacheDir.mkdirs()) { return DiskLruCacheWrapper.create(cacheDir, diskCacheSize); } return null ; }
这里cacheDirectoryGetter在InternalCacheDiskCacheFactory创建时被实例化,提供一个缓存文件,用于存取缓存资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public InternalCacheDiskCacheFactory ( final Context context, final String diskCacheName, long diskCacheSize) super ( new CacheDirectoryGetter() { @Override public File getCacheDirectory () File cacheDirectory = context.getCacheDir(); if (cacheDirectory == null ) { return null ; } if (diskCacheName != null ) { return new File(cacheDirectory, diskCacheName); } return cacheDirectory; } }, diskCacheSize); }
也就是factory.build函数需要获取到/data/data/<application package>/cache目录才能进一步通过DiskLruCacheWrapper.create(cacheDir, diskCacheSize)创建CacheFile。
1 2 3 4 5 protected DiskLruCacheWrapper (File directory, long maxSize) this .directory = directory; this .maxSize = maxSize; this .safeKeyGenerator = new SafeKeyGenerator(); }
到这里,那么``getDiskCache返回的就是DiskLruCacheWrapper对象,看看其getDiskCache`函数。
1 2 3 4 5 6 private synchronized DiskLruCache getDiskCache () throws IOException if (diskLruCache == null ) { diskLruCache = DiskLruCache.open(directory, APP_VERSION, VALUE_COUNT, maxSize); } return diskLruCache; }
也就是说,利用了DisLruChache来缓存资源。
假如factory.build返回是null,那么getDiskCache返回的是DiskCacheAdapter。
helper.getModelLoaders假设获取到了cacheFile,看看helper.getModelLoaders(cacheFile)函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 List<ModelLoader<File, ?>> getModelLoaders(File file) throws Registry.NoModelLoaderAvailableException { return glideContext.getRegistry().getModelLoaders(file); } public <Model> List<ModelLoader<Model, ?>> getModelLoaders(@NonNull Model model) { return modelLoaderRegistry.getModelLoaders(model); } public <A> List<ModelLoader<A, ?>> getModelLoaders(@NonNull A model) { List<ModelLoader<A, ?>> modelLoaders = getModelLoadersForClass(getClass(model)); if (modelLoaders.isEmpty()) { throw new NoModelLoaderAvailableException(model); } int size = modelLoaders.size(); boolean isEmpty = true ; List<ModelLoader<A, ?>> filteredLoaders = Collections.emptyList(); for (int i = 0 ; i < size; i++) { ModelLoader<A, ?> loader = modelLoaders.get(i); if (loader.handles(model)) { if (isEmpty) { filteredLoaders = new ArrayList<>(size - i); isEmpty = false ; } filteredLoaders.add(loader); } } if (filteredLoaders.isEmpty()) { throw new NoModelLoaderAvailableException(model, modelLoaders); } return filteredLoaders; }
helper.getModelLoaders(cacheFile)函数最终还是调用了ModelLoaderRegister.getModelLoaders函数,和前面分析得getChacheKeys是一致的,只是这里model是File.class。所以直接找到相关注册项。
1 2 3 4 5 .append(File.class, ByteBuffer.class, new ByteBufferFileLoader.Factory()) .append(File.class, InputStream.class, new FileLoader.StreamFactory()) .append(File.class, ParcelFileDescriptor.class, new FileLoader.FileDescriptorFactory()) .append(File.class, File.class, UnitModelLoader.Factory.<File>getInstance())
所以步骤3得到的modelLoaders列表为[ByteBufferFileLoader,FileLoader<InputStream>,FileLoader<ParcelFileDescriptor>,UnitModelLoader]
接下来步骤4,根据遍历modelLoaders列表的每个ModelLoader对象,尝试加载数据,直到找到第一个能处理该Glide请求的ModelLoader对象。
1 2 3 4 5 6 7 8 9 10 11 12 loadData = null ; boolean started = false ;while (!started && hasNextModelLoader()) { ModelLoader<File, ?> modelLoader = modelLoaders.get(modelLoaderIndex++); loadData = modelLoader.buildLoadData( cacheFile, helper.getWidth(), helper.getHeight(), helper.getOptions()); if (loadData != null && helper.hasLoadPath(loadData.fetcher.getDataClass())) { started = true ; loadData.fetcher.loadData(helper.getPriority(), this ); } }
看一下四个匹配到的ModelLoader的buildLoadData函数返回的LoadData对象中的DataFetcher对象fetcher。
ByteBufferFileLoader
返回的LoadDadata中的是ByteBufferFetcher(file),其getDataClass函数返回ByteBuffer.class。
FileLoader.StreamFactory()
返回的LoadDadata中的是FileFetcher<>(model, fileOpener),fileOpener是FileOpener<InputStream>类型,其getDataClass函数返回InputStream.class
FileLoader.FileDescriptorFactory()
返回的LoadDadata中的是FileFetcher<>(model, fileOpener)),fileOpener是FileOpener<ParcelFileDescriptor>类型,其getDataClass函数返回ParcelFileDescriptor.class
UnitModelLoader
返回的LoadDadata中的是UnitFetcher(file),其getDataClass函数返回File.class。
接下来看看helper.hasLoadPath(loadData.fetcher.getDataClass())这个函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 boolean hasLoadPath (Class<?> dataClass) return getLoadPath(dataClass) != null ; } <Data> LoadPath<Data, ?, Transcode> getLoadPath(Class<Data> dataClass) { return glideContext.getRegistry().getLoadPath(dataClass, resourceClass, transcodeClass); } public <Data, TResource, Transcode> LoadPath<Data, TResource, Transcode> getLoadPath ( @NonNull Class<Data> dataClass, @NonNull Class<TResource> resourceClass, @NonNull Class<Transcode> transcodeClass) LoadPath<Data, TResource, Transcode> result = loadPathCache.get(dataClass, resourceClass, transcodeClass); if (loadPathCache.isEmptyLoadPath(result)) { return null ; } else if (result == null ) { List<DecodePath<Data, TResource, Transcode>> decodePaths = getDecodePaths(dataClass, resourceClass, transcodeClass); if (decodePaths.isEmpty()) { result = null ; } else { result = new LoadPath<>( dataClass, resourceClass, transcodeClass, decodePaths, throwableListPool); } loadPathCache.put(dataClass, resourceClass, transcodeClass, result); } return result; }
所以主要看下getDecodePath函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 @NonNull private <Data, TResource, Transcode> List<DecodePath<Data, TResource, Transcode>> getDecodePaths( @NonNull Class<Data> dataClass, @NonNull Class<TResource> resourceClass, @NonNull Class<Transcode> transcodeClass) { List<DecodePath<Data, TResource, Transcode>> decodePaths = new ArrayList<>(); List<Class<TResource>> registeredResourceClasses = decoderRegistry.getResourceClasses(dataClass, resourceClass); for (Class<TResource> registeredResourceClass : registeredResourceClasses) { List<Class<Transcode>> registeredTranscodeClasses = transcoderRegistry.getTranscodeClasses(registeredResourceClass, transcodeClass); for (Class<Transcode> registeredTranscodeClass : registeredTranscodeClasses) { List<ResourceDecoder<Data, TResource>> decoders = decoderRegistry.getDecoders(dataClass, registeredResourceClass); ResourceTranscoder<TResource, Transcode> transcoder = transcoderRegistry.get(registeredResourceClass, registeredTranscodeClass); @SuppressWarnings("PMD.AvoidInstantiatingObjectsInLoops") DecodePath<Data, TResource, Transcode> path = new DecodePath<>( dataClass, registeredResourceClass, registeredTranscodeClass, decoders, transcoder, throwableListPool); decodePaths.add(path); } } return decodePaths; }
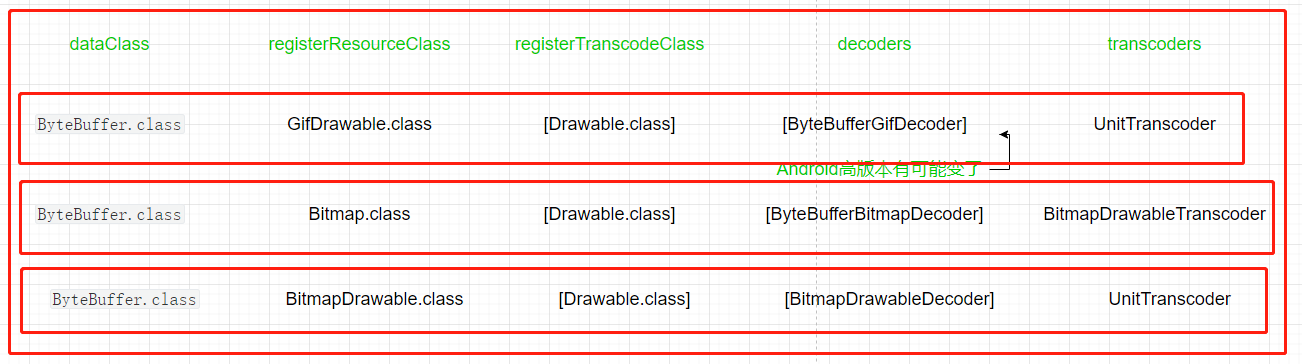
getDecodePaths函数中几个函数已经分析过了,说一下大概逻辑,resourceClass=Object.class、transcodeClass=Drawable.class。从ModelLoader列表开始,第一个dataClass取ByteBufferFileLoader的ByteBuffer.class。
先通过dataClass和resourceClass去获取registerResourceClass列表。利用前面整理的Excel文件,筛选一下。
去掉重复的,再根据Key的优先级排序,那么得到的registerResourceClass=[GifDrawable.class,Bitmap.class、BitmapDrawable.class]
遍历registerResourceClass列表,通过registeredResourceClass和transcodeClass获取registeredTranscodeClasses列表。
由于是遍历registerResourceClass列表,将会生成三个registeredTranscodeClasses列表。根据transcoderRegistry.getTranscodeClasses函数内容的处理规则,这个三个列表是相同的,且只持有一个Drawable.class元素。
然后再迭代每个registeredTranscodeClasses列表。
根据dataClass和registeredResourceClass获取decoders列表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public synchronized <T, R> List<ResourceDecoder<T, R>> getDecoders( @NonNull Class<T> dataClass, @NonNull Class<R> resourceClass) { List<ResourceDecoder<T, R>> result = new ArrayList<>(); for (String bucket : bucketPriorityList) { List<Entry<?, ?>> entries = decoders.get(bucket); if (entries == null ) { continue ; } for (Entry<?, ?> entry : entries) { if (entry.handles(dataClass, resourceClass)) { result.add((ResourceDecoder<T, R>) entry.decoder); } } } return result; }
根据registeredResourceClass和registeredTranscodeClass获取transcoder列表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public synchronized <Z, R> ResourceTranscoder<Z, R> get ( @NonNull Class<Z> resourceClass, @NonNull Class<R> transcodedClass) if (transcodedClass.isAssignableFrom(resourceClass)) { return (ResourceTranscoder<Z, R>) UnitTranscoder.get(); } for (Entry<?, ?> entry : transcoders) { if (entry.handles(resourceClass, transcodedClass)) { return (ResourceTranscoder<Z, R>) entry.transcoder; } } throw new IllegalArgumentException( "No transcoder registered to transcode from " + resourceClass + " to " + transcodedClass); }
通过ResourceRegister.getDecoders函数和TranscodeRegister.get函数逻辑,再加上整理出的Excel表格,可以得出decoders列表和transcoders列表内容。
然后包装成DecodePath元素,添加到decodePaths列表中。最后将decodePaths列表返回。也就是图中三条横线边框就是三条DecodePath,这个方框就是decodePaths。
回到startNext函数的步骤4中的helper.hasLoadPath(loadData.fetcher.getDataClass())返回true,然后调用fetcher.loadData函数加载数据。
fetcher.loadData这里的fetcher通过上面的分析就是ByteBufferFetcher。查看loadData函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 public void loadData ( @NonNull Priority priority, @NonNull DataCallback<? super ByteBuffer> callback) ByteBuffer result; try { result = ByteBufferUtil.fromFile(file); callback.onDataReady(result); } catch (IOException e) { if (Log.isLoggable(TAG, Log.DEBUG)) { Log.d(TAG, "Failed to obtain ByteBuffer for file" , e); } callback.onLoadFailed(e); } }
通过ByteBufferUtil.fromFile(file)正常的文件读取操作获取ByteBuffer数据。然后通过callback.onDataReady(result)回调。ResourceCacheGenerator.startNext函数也到此结束,完结撒花。
ResoucrCacheGenerator小结ResoucrCacheGenerator主要通过DataFetcher从缓存文件获取采样和转化的数据资源。其startNext函数主要是通过modelClass和resourceClass、transcodeClass去获取合适的modelLoader、decoder和transcoder,并构成DecodePaths。这样在回调中,就可以通过这些Paths寻找到合适的去加载数据并采样,转化资源。
DataCacheGenerator初始加载,那么ResoucrCacheGenerator.startNext函数将返回false,回到DecodeJob的runGenerators函数。此时获取到下一个Stage是Stage.DATA_CACHE,Generator是DataCacheGenerator。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 private void runGenerators() { currentThread = Thread.currentThread(); startFetchTime = LogTime.getLogTime(); boolean isStarted = false; while (!isCancelled && currentGenerator != null && !(isStarted = currentGenerator.startNext())) { stage = getNextStage(stage);//这里返回将是Stage.DATA_CACHE currentGenerator = getNextGenerator();//这里返回的将是DataCacheGenerator if (stage == Stage.SOURCE) { reschedule(); return; } } if ((stage == Stage.FINISHED || isCancelled) && !isStarted) { notifyFailed(); } } public void reschedule() { runReason = RunReason.SWITCH_TO_SOURCE_SERVICE; callback.reschedule(this); }
查看DataCacheGenerator的startNext函数。由于前面分析了ResourceCacheGenerator,所以下接下来回轻松很多。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public boolean startNext () while (modelLoaders == null || !hasNextModelLoader()) { sourceIdIndex++; if (sourceIdIndex >= cacheKeys.size()) { return false ; } Key sourceId = cacheKeys.get(sourceIdIndex); Key originalKey = new DataCacheKey(sourceId, helper.getSignature()); cacheFile = helper.getDiskCache().get(originalKey); if (cacheFile != null ) { this .sourceKey = sourceId; modelLoaders = helper.getModelLoaders(cacheFile); modelLoaderIndex = 0 ; } } loadData = null ; boolean started = false ; while (!started && hasNextModelLoader()) { ModelLoader<File, ?> modelLoader = modelLoaders.get(modelLoaderIndex++); loadData = modelLoader.buildLoadData( cacheFile, helper.getWidth(), helper.getHeight(), helper.getOptions()); if (loadData != null && helper.hasLoadPath(loadData.fetcher.getDataClass())) { started = true ; loadData.fetcher.loadData(helper.getPriority(), this ); } } return started; }
ResourceCacheGenerator查找到的cacheKeys会保存在DecodeHelper中,避免每次都需要重新寻找。DataCacheGenerator的主要作用从缓存资源中获取原始数据,其startNext函数与ResocurceCacheGenerator非常相似,这里不作展开。
SourceGeneator回到DecodeJob的runGenerators函数,那么将执行SourceGenerator函数,从数据来源获取数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public boolean startNext () if (dataToCache != null ) { Object data = dataToCache; dataToCache = null ; cacheData(data); } if (sourceCacheGenerator != null && sourceCacheGenerator.startNext()) { return true ; } sourceCacheGenerator = null ; loadData = null ; boolean started = false ; while (!started && hasNextModelLoader()) { loadData = helper.getLoadData().get(loadDataListIndex++); if (loadData != null && (helper.getDiskCacheStrategy().isDataCacheable(loadData.fetcher.getDataSource()) || helper.hasLoadPath(loadData.fetcher.getDataClass()))) { started = true ; startNextLoad(loadData); } } return started; }
在前面分析中,helper.getLoadData()这里返回的是LoadData列表只有一个LoadData元素,而且其DataFetcher是MultiFetcher对象。且MultiFetcher对象持有HttpUrlFetcher对象。
再看上面代码,helper.getDiskCacheStrategy().isDataCacheable函数,默认情况下DiskCacheStrategy是AUTOMATIC。
1 2 3 public boolean isDataCacheable (DataSource dataSource) return dataSource == DataSource.REMOTE; }
再看MultiFetcher的getDataSource函数。
1 2 3 public DataSource getDataSource () return fetchers.get(0 ).getDataSource(); }
调用HttpUrlFetcher的getDataSource函数,其返回的也是DataSource.REMOTE,所以该条件成立。
1 2 3 public DataSource getDataSource () return DataSource.REMOTE; }
而getDataClass返回的是InputStream.class
1 2 3 public Class<InputStream> getDataClass () return InputStream.class; }
startNextLoad(loadData)查看startNextLoad(loadData)函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 private void startNextLoad (final LoadData<?> toStart) loadData.fetcher.loadData( helper.getPriority(), new DataCallback<Object>() { @Override public void onDataReady (@Nullable Object data) if (isCurrentRequest(toStart)) { onDataReadyInternal(toStart, data); } } @Override public void onLoadFailed (@NonNull Exception e) if (isCurrentRequest(toStart)) { onLoadFailedInternal(toStart, e); } } }); }
MultiFetcher的loadData函数。
1 2 3 4 5 6 7 8 9 10 public void loadData (@NonNull Priority priority, @NonNull DataCallback<? super Data> callback) this .priority = priority; this .callback = callback; exceptions = throwableListPool.acquire(); fetchers.get(currentIndex).loadData(priority, this ); if (isCancelled) { cancel(); } }
调用HttpUrlFetcher的loadData函数。在loadData函数中,获取输入流无论成功与败将通过callback回掉通知。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public void loadData ( @NonNull Priority priority, @NonNull DataCallback<? super InputStream> callback) long startTime = LogTime.getLogTime(); try { InputStream result = loadDataWithRedirects(glideUrl.toURL(), 0 , null , glideUrl.getHeaders()); callback.onDataReady(result); } catch (IOException e) { if (Log.isLoggable(TAG, Log.DEBUG)) { Log.d(TAG, "Failed to load data for url" , e); } callback.onLoadFailed(e); } finally { if (Log.isLoggable(TAG, Log.VERBOSE)) { Log.v(TAG, "Finished http url fetcher fetch in " + LogTime.getElapsedMillis(startTime)); } } }
可见调用了loadDataWithRedirects函数并返回了数据。loadDataWithRedirects函数主要是通过HttpURLConnection来进行网络请求,并获取数据。同时也允许重定向,但次数不能超过5次。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 private InputStream loadDataWithRedirects ( URL url, int redirects, URL lastUrl, Map<String, String> headers) throws HttpException if (redirects >= MAXIMUM_REDIRECTS) { throw new HttpException( "Too many (> " + MAXIMUM_REDIRECTS + ") redirects!" , INVALID_STATUS_CODE); } else { ... urlConnection = buildAndConfigureConnection(url, headers); try { urlConnection.connect(); stream = urlConnection.getInputStream(); } catch (IOException e) { throw new HttpException( "Failed to connect or obtain data" , getHttpStatusCodeOrInvalid(urlConnection), e); } if (isCancelled) { return null ; } final int statusCode = getHttpStatusCodeOrInvalid(urlConnection); if (isHttpOk(statusCode)) { return getStreamForSuccessfulRequest(urlConnection); } else if (isHttpRedirect(statusCode)) { String redirectUrlString = urlConnection.getHeaderField(REDIRECT_HEADER_FIELD); if (TextUtils.isEmpty(redirectUrlString)) { throw new HttpException("Received empty or null redirect url" , statusCode); } URL redirectUrl; try { redirectUrl = new URL(url, redirectUrlString); } catch (MalformedURLException e) { throw new HttpException("Bad redirect url: " + redirectUrlString, statusCode, e); } cleanup(); return loadDataWithRedirects(redirectUrl, redirects + 1 , url, headers); } else if (statusCode == INVALID_STATUS_CODE) { throw new HttpException(statusCode); } else { try { throw new HttpException(urlConnection.getResponseMessage(), statusCode); } catch (IOException e) { throw new HttpException("Failed to get a response message" , statusCode, e); } } }
步骤1:通过connectionFactory.build函数创建了HttpURLConenction实例,并配置了相关信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 private HttpURLConnection buildAndConfigureConnection (URL url, Map<String, String> headers) throws HttpException { HttpURLConnection urlConnection; try { urlConnection = connectionFactory.build(url); } catch (IOException e) { throw new HttpException("URL.openConnection threw" , 0 , e); } for (Map.Entry<String, String> headerEntry : headers.entrySet()) { urlConnection.addRequestProperty(headerEntry.getKey(), headerEntry.getValue()); } urlConnection.setConnectTimeout(timeout); urlConnection.setReadTimeout(timeout); urlConnection.setUseCaches(false ); urlConnection.setDoInput(true ); urlConnection.setInstanceFollowRedirects(false ); return urlConnection; }
这里的ConnectionFactory实例我们使用了默认的DefaultHttpUrlConnectionFactory。其build函数通过Url.openConnection返回了一个网络连接。
1 2 3 public HttpURLConnection build (URL url) throws IOException return (HttpURLConnection) url.openConnection(); }
在判断请求成功,通过getStreamForSuccessfulRequest函数去获取输入流。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 private InputStream getStreamForSuccessfulRequest (HttpURLConnection urlConnection) throws HttpException { try { if (TextUtils.isEmpty(urlConnection.getContentEncoding())) { int contentLength = urlConnection.getContentLength(); stream = ContentLengthInputStream.obtain(urlConnection.getInputStream(), contentLength); } else { if (Log.isLoggable(TAG, Log.DEBUG)) { Log.d(TAG, "Got non empty content encoding: " + urlConnection.getContentEncoding()); } stream = urlConnection.getInputStream(); } } catch (IOException e) { throw new HttpException( "Failed to obtain InputStream" , getHttpStatusCodeOrInvalid(urlConnection), e); } return stream; }
到这里,也就从网络获取到图片的输入流,我们到此告一段落。
把Glide数据来源整理一下,也是Glide的缓存机制。接下来的章节也将继续分析下图的问号?
缓存总的来说应该只有内存缓存和硬盘缓存。而Glide在两个缓存上再各细分出两个缓存,总得来说就有四个缓存了。